
VNL-ATK 2015 版已经于 2015年10月21日正式发布,此版本包含了众多的新功能和显著的性能提升。
新功能概览
- 电子-声子相互作用
- 计算非弹性的电流、畸变势和迁移率
- 新的作业管理工具
- 可以向本机或远程服务器提交串行、并行计算任务(【详情】)
- 新的分子动力学(MD)和离子动力学功能
- 图形界面上新增多种MD结果分析函数,例如速度自相关函数、角分布函数、均方位移等
- 使用动量交换的非平衡态分子动力学(NEMD)计算(器件体系)热导
- 全新的刚体+一维最小化方法优化界面和器件结构
- 全局优化算法(用于晶体结构和相稳定性预测)
- ATK-Classical中新增core-shell等多种势函数
- NEB计算的并行化
- 适应性动力学蒙特卡洛(KMC)模块,可以用于寻找反应路径,估计反应速率指前因子(HTST)以及粗粒化时间加速的MD
- 半导体材料模拟新功能
- DFT计算的虚晶近似(VCA)
- 随机合金等体系超胞的有效能带分析
- MGGA-TB09中可以对不同材料指定不同的c参数
- 图形界面上新的掺杂小工具
- 性能与并行计算提升
- 大幅提高计算和并行性能(充分使用稀疏矩阵技术),减少计算的内存和时间需求
- VNL图形界面现可以处理百万数量级原子数体系
- NEB计算基于路径上结构数的并行(较上一版本提速最多25倍)
- FHI-aims的Python接口
- VNL支持其他计算代码
- LAMMPS:导入、导出几何结构,用VNL的图形界面的MD分析工具和动画工具分析结果
- Quantum ESPRESSO:导入导出工具,分析电子密度、态密度、能带等结果
- 增强VASP计算接口
- VNL中嵌入OpenBabel支持
马上下载VNL-ATK 2015.0!
使用许可(License)
- 为运行此版本的软件,您的license文件中需要明确支持15.0或更高。我们将向所有购买时承诺更新至2015新版的用户提供免费更换license的升级服务。VNL-ATK的老版本用户可以付费升级,请与我们联系。
- 学术用户可以免费获得VNL图形界面的license。
- 为运行ATKClassical或在Builder中使用此功能,license文件中需要包含ATKClassical的信息,此功能免费向学术用户提供(学术用户的免费VNL图形界面使用许可也包含此功能),也可以与其他计算功能一同购买。
- FHI-aims功能需要单独授权,欢迎与我们联系。
- VASP接口(含生成输入文件、分析输出文件等功能)需要license文件中包含ATKVASP功能。所有购买了ATK-DFT/SE的用户都将免费获得此功能。VNL图形界面用户可单独购买VASP接口license,欢迎与我们联系。(注意:用户需自行获得VASP使用授权并正确编译安装。QuantumWise和费米科技都不提供任何形式的VASP代码和使用许可。)
- 其他感兴趣的老师和同学,欢迎与我们联系获得全功能的试用许可。
VNL-ATK 2015新功能
电子声子耦合
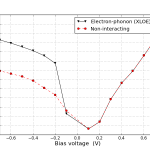
此图比较了硅pn结的弹性和非弹性伏安特性曲线,显示了带间隧穿(BTBT)电流由于(光学)声子散射得到了增强。
- Quasi-inelastic(LOE)和fully inelastic XLOE 电声散射电流电压关系
- 可以使用ATK内提供的各种理论方法进行电子和晶格部分的计算
- 使用DFT、SE等计算电子部分
- 使用DFT、DFTB、经验势等计算声子(DFT计算声子可能非常耗时)
- 块体材料导出电子-声子散射矩阵
- 计算畸变势和迁移率(玻尔兹曼方程)
- 不限于弛豫时间近似
- 参考计算实例教程
- 参考文献
- Thomas Frederiksen, Markus Paulsson, Mads Brandbyge, and Antti-Pekka Jauho, Phys. Rev. B 75, 205413 (2007)
- Jing-Tao Lü, Rasmus B. Christensen, Giuseppe Foti, Thomas Frederiksen, Tue Gunst, and Mads Brandbyge, Phys. Rev. B 89, 081405(R) (2014)
- Kristen Kaasbjerg, Kristian S. Thygesen, and Karsten W. Jacobsen, Physical Review B 85.11, 115317, (2012)
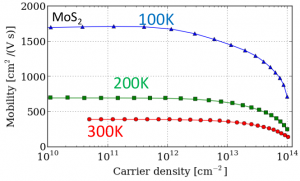
MoS2中受到声子限制的电子迁移率随载流子浓度的变化。
新的作业管理器
- 在本机或远程服务器上提交串行或并行计算

新的作业管理器界面。
- 本机模式:串行、多线程、并行
- 远程模式:Torque/PBS队列系
统、无队列系统直接提交(【详情】)
- 自动上传输入文件、下载输出文件
- 无需服务器端的守护进程
- 仅需要安全的ssh访问
离子动力学
ATK-Classical更新
- 速度提升(2倍)
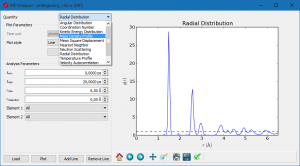
MD结果分析的几种新功能。
- 新的经验势种类
- Madden
- Core-shell
- COMB
- 更好的处理长程势,以进行声子计算
- 可以用原子标签功能设置不同的势函数
- 部分电荷分析
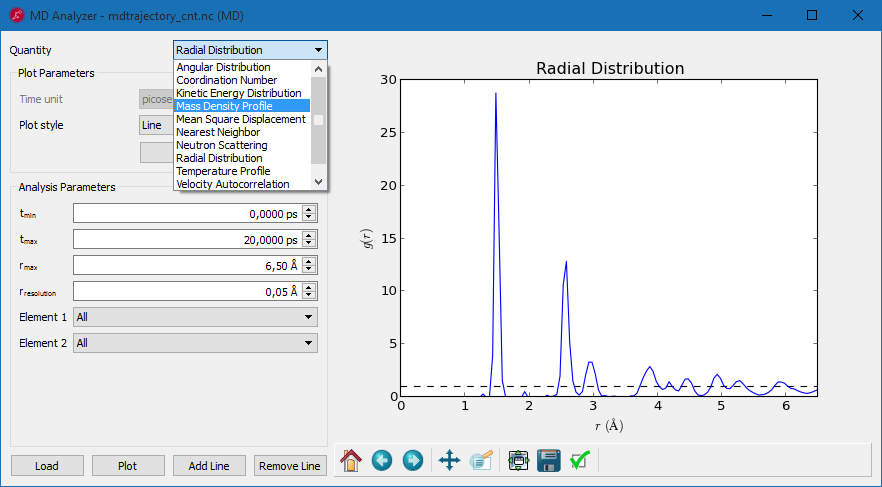
结构优化、NEB
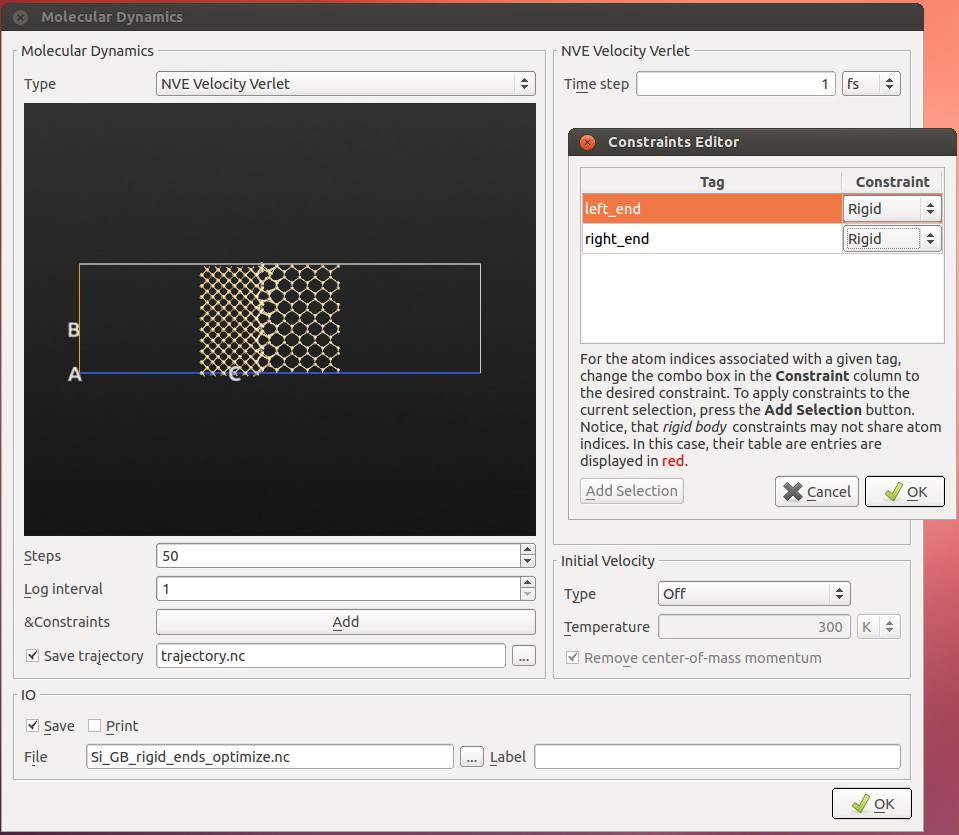
新的设置几何结构限制的工具(如刚性关系),可以用于MD和结构优化。
- 重写了NEB和LBFGS算法,由于改进了收敛性和代码集成,平均提速2倍
- NEB现可以通过多个中间结构并行(比2014版本提速最多25倍)
- 新的全局优化算法(晶体结构预测工具)
- 目标应力方法(在外加应力的情况下优化结构)
- 新的动态矩阵方法,可以保存动态矩阵对象
- 压电张量计算现在支持内部离子位置优化,对AlN等材料非常重要
- 新的结构优化方法:将一组原子设置为刚性,不优化原子相对位置关系。也可以限制原子在某一方向
- 全新的优化界面结构的方法(采用器件模型),见实例教程
- 对研究器件体系特别重要
- 现在Scrpt Generator里可以非常方便的使用“tag”功能设置结构限制条件,支持设置冻结原子坐标或刚性原子位置关系
- 动态矩阵计算时可以自动确定晶胞重复的倍数
分子动力学
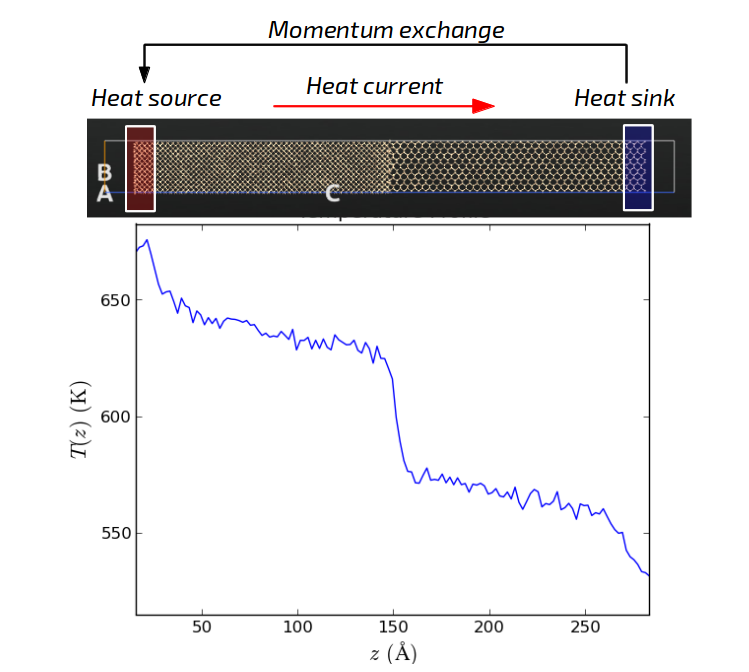
NEMD方法计算的界面温度变化和热导情况。
- MD计算性能提升(NPT和Velocity Verlet提升2倍速度)
- 新的NVT方法,使用Nose-Hoover chain来避免温度振荡
- 通过设定目标温度自动选择加热或冷却曲线
- 可控制局域温度、设定升温速率
- 新的MD轨迹结果分析功能
- 速度自相关函数
- 局域质量密度分布
- 从MD轨迹计算声子DOS
- 配位数
- 角分布函数
- 均方位移
- Evolution of average nearest neighbor number with tine
- 中子散射结构因子
- LAMMPS和VASP MD结果导入并用上述工具分析
- 在MD分析中,可以选择部分原子(目前通过脚本实现)
- 在角分布的分析中为两种元素对指定不同的截断半径
- 更多MD分析功能改进
- 可对单个结构进行RDF、配位数等分析
- 多种函数重叠作图
- 在柱状图基础上新增线状图
- 显示MD模拟过程的原子速度
- 使用MD计算热导(卡皮查界面热导)
- 参见实例教程
- 动画工具改进
- 可选时间单位
- 图例仅包括激活的曲线
- 导出数据按列显示
适应性动力学蒙特卡洛模拟(AKMC)
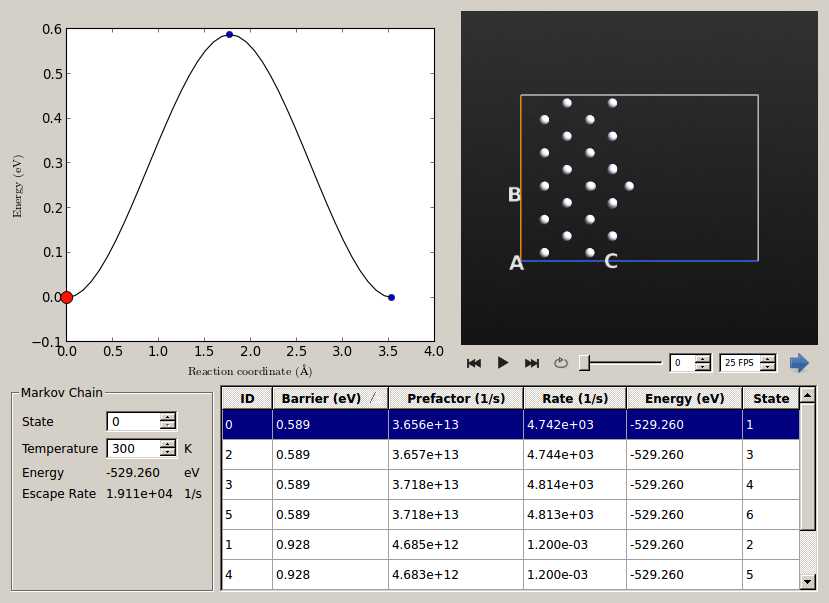
VNL中的Markov链分析工具,用于研究KMC的结果。
- 全新的AKMC模块,与UTAustin 的 Henkelman 组合作完成(http://theory.cm.utexas.edu/eon/akmc.html)
- 仅基于初始构型自动寻找可能的反应路径(尤其是鞍点)(NEB方法需要知道初始和最终两个构型)
- 由声子配分函数计算反应速率的指前因子(简谐过渡态理论,HTST),可以用于估计扩散系数等
- 采用加速时间演化方案将MD模拟扩展至长时域(毫秒甚至秒)(Markov链粗粒化)
- 参见实例教程
模拟半导体材料的新功能
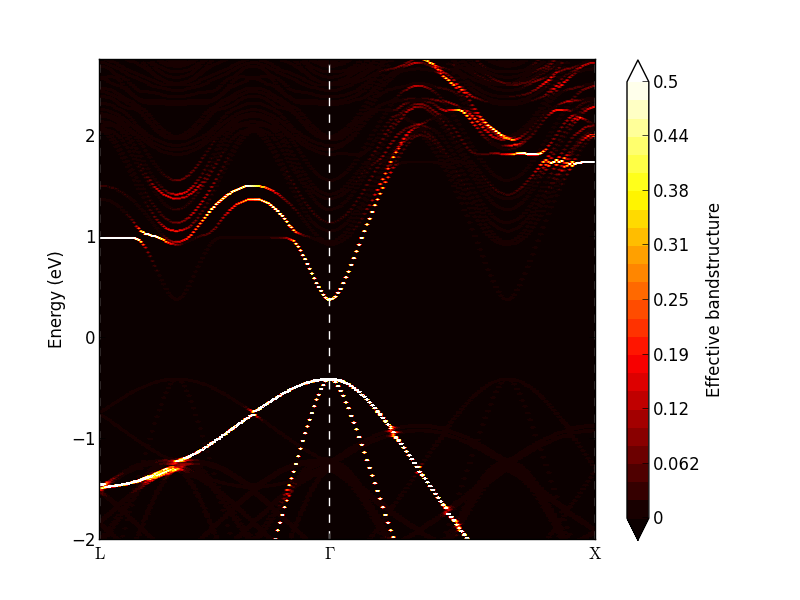
In_{0.53}Ga_{0.47}As的有效能带结构(用DFT-MGGATB09计算)。
- DFT 虚晶近似(VCA)
- 随机合金体系超胞的有效能带分析
- MGGA-TB09按不同区域设置不同的c参数,可以研究两种半导体材料构成的界面,分别设置c参数以反映不同的能隙
- 在Bassani和Vogl 的 Slater-Koster基组中增加氢原子,可以模拟钝化的表面
- Builder中增加原子补偿电荷掺杂工具
- 电子输运方向的Neumann边界条件(仅在有门电极的情况下,否则电势绝对值不确定)
- 更方便的作LDOS随z方向的变化图(不同位置能带图)
- 有效质量功能更新
- 新方法基于二阶微扰理论
- 非抛物线能带分析,可以与TCAD工具联用
性能改进
新版本重点优化了内存使用(尤其是在多个并行节点上分布),并成功的提高了并行效率。敬请期待性能测试结果。
计算性能与并行化
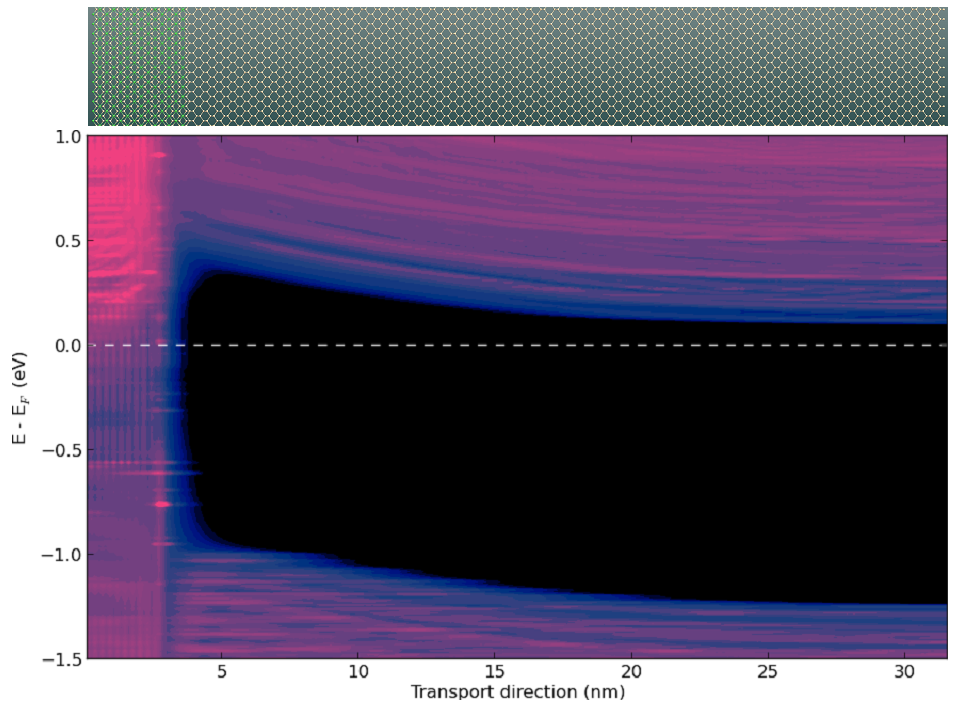
ATK2015现可以模拟30-40nm长的器件。这里显示的是Ag和n-Si之间形成的肖特基势垒。图中可以看出,屏蔽距离远远超出一般的slab模型的模拟。
- 新增并行化的稀疏矩阵库,用于矩阵运算
- 将单个k点并行在多核上
- 允许MPI并行多于k点数,得到的最高达10倍的性能提升,每个k点的对角化可以基于ELPA进行共享内存的并行化
- 新的对角化参数,仅包括费能级以上部分能带,可以使大体系的超胞计算提速2倍
- 可选缓存能量密度矩阵,加速结构优化
- 可选缓存轨道和基函数,大大提升性能
- 对于小体系,内存需求是合理的,因为实空间的积分占主要部分;但对于大体系,内存需求可能很大,因为SCF的其他部分占主要部分
- log文件将显示内存使用情况(查看Real space integral部分的耗时,使用此方案可能会大大减少)
- 自洽循环的并行历史记录
- 大大节省内存
- 器件DDOS和LDOS计算由于避免了密度矩阵,大大减少内存需求
- 升级MKL至11.2,矩阵运算平均提速5-10%(甚至45%)
- Contour积分的多级别并行,对于大的器件体系可以大大减少内存需求,允许更多的并行节点数
- GGA的FFT版本,5倍效率提升,计算时间与LDA接近

使用ATKClassical可以模拟百万数量级的原子体系,当然VNL图形界面现在可以流畅的操作、绘制巨型体系结构。图中显示的是HfO2的多晶结构,包含120万的原子。
- 稀疏矩阵求逆的新算法(ZMUMPS)。比较粗的器件体系格林函数计算提速2-5倍、内存需求减少20-25倍
- 直接求解Poisson方程可以用磁盘缓存,减少峰值内存使用
- 临近原子列表优化,对于50万原子体系提速25倍
- 非自洽的Slater-Koster计算并行化
- 试验功能:FEAST稀疏矩阵并行对角化,自动确定子空间间隔
- 试验功能:Chebyshev多项式O(N)方法
重要提醒:在一个节点上进行多MPI进程并行计算时,应在脚本中设置 MKL_NUM_THREADS=1,否则可能影响计算性能。
VNL图形界面性能
- 3D图形显示
- VNL现在可以轻松处理百万级原子数体系(普通的显卡)
- 巨型体系的操作优化
- 可选二维渲染以进一步提升性能(实例演示了八百万原子)
- 使用OpenGL shader更好更快的作等值面图
- 可选降低等值面图的渲染质量,更快的调节等值面值
- 可以将键画为细线,对于大体系大大改进性能
- 基于shader方法渲染三维切面和等高线
- 键关系列表计算大大提速
- 大体系的加载速度大大提升
- “Device from bulk”功能显著改进
- 对于大体系提速50-150倍
- 内存泄露等问题优化
- Builder中多个工具改进,以支持百万级原子数体系
- Interface Builder 重大改进
- 钝化工具重大改进
- VNL-ATK启动速度优化
VNL图形界面的更新
新的Builder、Viewer、LabFloor插件和功能
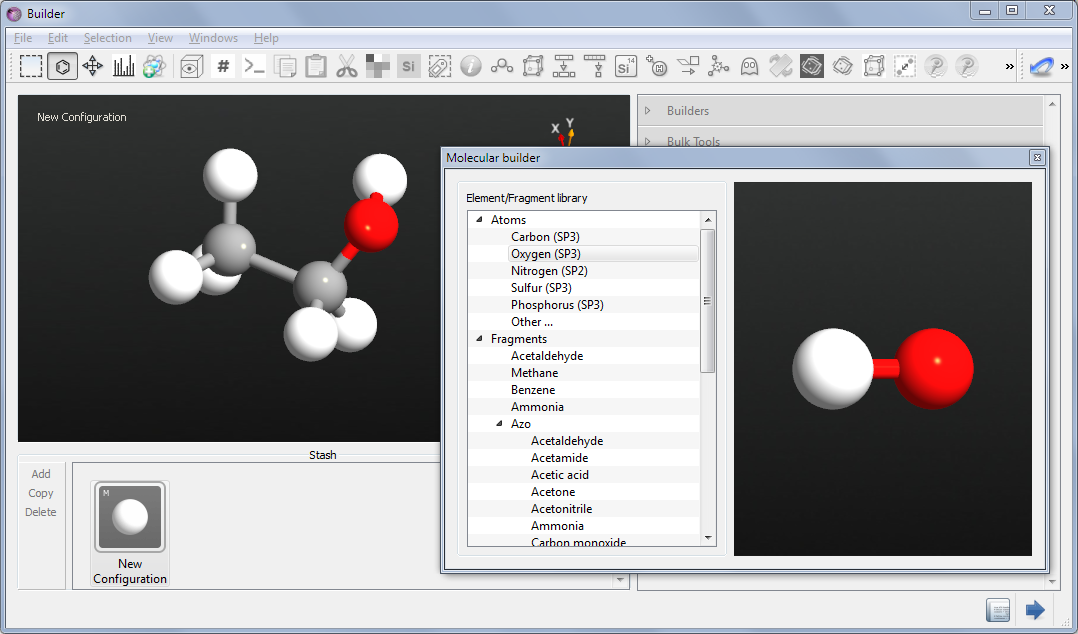
分子建模工具。
- 新的分子建模工具:可以使用化学概念构建分子并放置在表面上
- 新的超胞掺杂建模工具,构建填隙和替位的随机合金
- 椭圆和二次方鼠标选择工具
- Builder和Viewer中更方便的“select by element”
- 界面建模工具
- 改变界面距离时保持周期性
- 使用经验势预优化界面结构
- 自动添加左右部分的标签
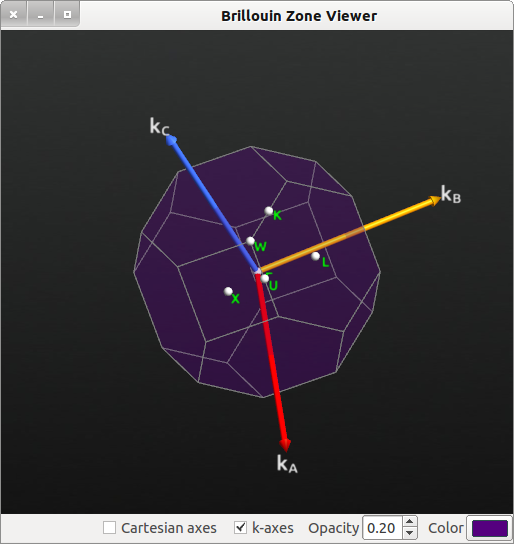
- 布里渊区查看工具
- 更多Builder里的工具在Viewer里也支持
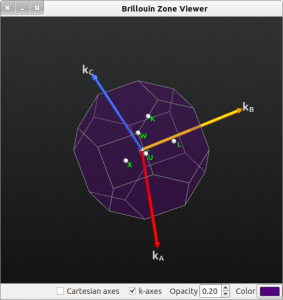
布里渊区查看工具。
- 新的LabFloor工具:Compare data,用于将两个DOS或能带一起作图比较
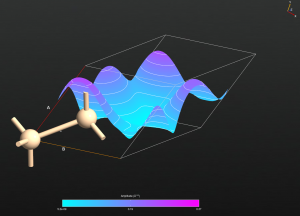
3D作图
- 性能大大改进(见上文
- 显示键的提示信息(键长和连接的原子)
- Builder中现支持图形属性设
- 化学键
- 所有化学键都画出
- 用参数控制原子间的键是否画出
- 打开、关闭键的显示
- Stash里的结构会保存键的显示设置
- Ghost atom用新方法显示
- 晶格的轴标签(ABC)可以编辑
- 结构、等值面和切面图都可以重复显示
- 新的3D作图选项
- contour切面的深度作图
- contour作图添加等值线
- 3D地形图显示格点数据
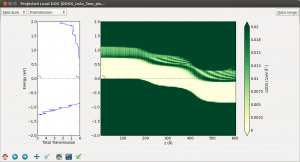
3D作图和等高线可以更方便、清楚的显示几种格点数据(如电势和电子密度)。这些作图工具也适用于VASP或其他代码的结果。
- Contour图的颜色可以只显示部分数据范围
- 重置图形显示为默认设置
- 更好的支持老型号显卡
- VNL可以检查OpenGL版本过低,并给出警告信息
新平台特性
- LAMMPS
- 导入导出工具
- MD轨迹分析工具
- QuantumEspresso
- 导入导出工具,电子密度、能带、DOS分析工具
- 参见实例教程
- VNL中包含OpenBabel,允许导入导出无数的化学结构文件
- VASP

- 显示振动模式
- 改进导入MD轨迹
- 新的设置冻结原子的图形界面工具
- 更合理的VASP输入文件默认值
- INCAR文件预览

- 手动增加INCAR文件行
- 更方便的识别VASP结果
- GPAW
- 导入、导出文件,分析电子密度

- 导入、导出文件,分析电子密度
FHI-aims
- 最新的FHI-aims嵌入在ATK 2015中
- 新的Python接口可以使用几乎全部FHI-aims功能
- 图形界面支持
- 注:此功能需要单独购买license
- 具体功能参考FHI-aims官网:https://aimsclub.fhi-berlin.mpg.de/index.php
通用功能改进
- 非共线自旋算法有很多改进
- 从自旋非极化计算的密度开始进行自旋轨道耦合、非共线自旋计算
- 增加分析计算工具SpinTransferTorque
- 实现对分子和块体进行限制性自旋DFT计算
- 适用于研究磁各向异性
- Gimme-D3色散力(范德华力)校正
- 可选增加三体项(非常耗时)
- Python实现的并行化排程:用户可以实现脚本内的计算任务并行化(如门电极电压扫描等)
- 静态方式:计算任务列表固定不变,master可以处理计算
- 动态方式:计算任务列表由master动态分配,可以更好的平衡负载,因此master不处理计算
- 首个单电极概念模拟(配合无限大基底表面模型)
- 精确功函数计算,计算速度(16核)比用VASP的(64核)计算速度快20倍
- 可以更准确描述从基底向(带有吸附分子的)表面的电荷转移
- 适应性k空间积分方案:用更少的k点得到更精确的电流,尤其是T(E,k)有比较尖的窄峰时
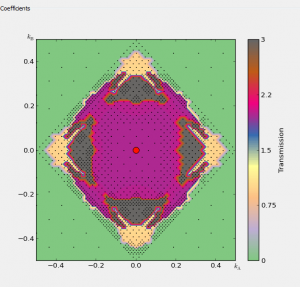
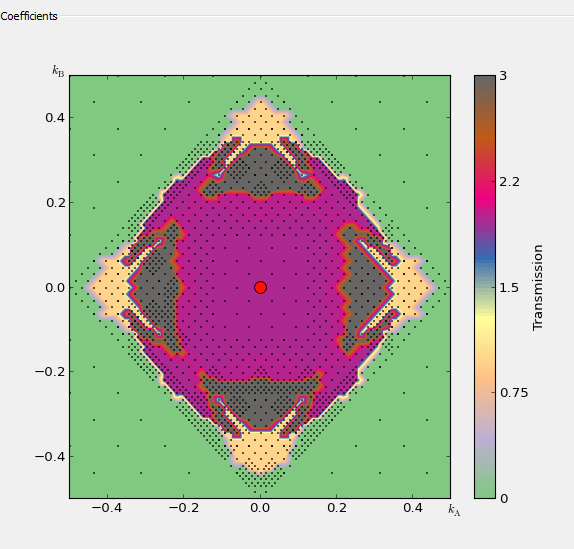
- 谱电流作图,可以在透射谱或谱电流的旁边画出空间投影的LDOS/PDOS
- 新增使用格点数来定义FFT网格选项
- 在连续改变晶格常数进行应力优化时特别重要。基于格点间隔原有方案会在晶格常数的变化过程中带来格点数的变化,进而使能量发生不一致的突变情况,难以得到好的优化结果
- Dirichlet/Neumann边界条件用于功函数或其他slab模型计算,现只要一个方向的格矢垂直于另外两个方向即可
- ATK中STM模块的第一个版本(不仅限于Hamann-Tersoff模型)
- 基组和精度
- 收缩和普通型的OMX基组在delta测试中可以给出非常精确的结果。含旋轨耦合的完全的相对论描述
- Delta测试模块
- 支持ONCV和UPF2赝势格式
其他小的更新
- NEB初始路径方法中“BC”现改名为“IDPP”
- Editor字体可变
- GridOptions:格点数据现可以进行一个常数的乘法或除法运算
- 用于自定义自旋劈裂DFTB基组参数的类型
- 局域结构的操作变化
- LowLevelEntities现在可以用于非共线和旋轨耦合计算
- 增加更多晶体结构数据
- 在Viewer窗口标题中增加显示的数据信息
- Abinit计算分析Bloch态
- MullikenPopulation对象现包含结构,方便可视化
- 现可以导入分数坐标的CIF文件(仍可能包含重叠的原子)
- 增加自己从numpy矩阵创建GredValues对象的功能
- Nanowire现在创建为UnitCell类型
- ATK现在自动探测OpenMPI并停止运行:仅当使用MPICH2兼容的MPI库时才运行
- LocalStress作图改进
- 修改数据范围以更好的颜色显示
- 单独作图某一分量
安装包和license系统变化
- VNL和ATK在Windows系统里从不同的PATH启动
- PyQt现支持命令行:用户可以自己写“applets”
- 安装过程不再配置license
- 若启动时没有license,VNL会自动访问网络获取14天试用license
- 安装包现经过发布者签名
- VNL启动时自动检查获取插件的更新
- 可以停用插件,不必直接删除
- 本地安装插件(用户本人无法直接控制VNL的安装)
- 暂无Mac OS X版的VNL-ATK2015
其他问题修复
- ATK2014中的OMX基组存在振荡的拖尾,现已在2015中修复,可以改进计算精度,但可能导致OMX基组在2014和2015的计算中给出微小的结果差别
- 其他小的bug修复